THND OCR The Series Season 1 Version ม้วนเดียวจบบบบ อะเห้ยย 👾
บทความนี้จะเป็นการพูดถึงภาพรวม ที่มาและ ความสำคัญของการพัฒนาโปรเจค TH National Document OCR (THND OCR) ในงาน AI Builders a program for kids who want to build good AI 💕
Github Repo : https://github.com/copninich/TH-National-Document-OCR
Website for testing : http://xeondevx.trueddns.com:49349/ or https://thndocr.herokuapp.com/
- OCR คืออะหยังอะ ?

หลายๆคน ในทีนี้อาจจะยังสงสัย หรือ เพิ่งเคยได้ยิน คำว่า OCR ซึ่งจริงแล้ว OCR (Optical Character Recognition) คือการรู้จำอักขระด้วยแสง โดย Process หรือกระบวนการทำงานของ OCR นั้น เราจะมีในส่วนของ Input คือ ตัวเอกสารที่ผ่านการสแกน การถ่ายภาพ มา ในสกุลไฟล์ต่างๆ เช่น .jpg .png .pdf เป็นต้น จากนั้นจะเข้าสู่กระบวนการแปลงตัวอักษรจากรูปภาพ ให้เป็น ตัวอักษร Character ในคอมพิวเตอร์
2. ความสำคัญของ OCR สู่ Project การทำ OCR เอกสารราชการไทย ?
ในปัจจจุบันได้มีการนำเทคโนโลยีการจำรู้อักขระด้วยแสง หรือ OCR มาประยุกต์ใช้ในงานต่างๆ อย่างมากมายหลายๆแพลตฟอร์ม พยายาม Apply OCR เข้าไปใช้เพื่ออำนวยความสะดวก สบายให้กับผู้ใช้งานแพลตฟอร์มแต่เมื่อเรามาพูดถึงเอกสารราชการ หลายคนจะนึกถึงเอกสารที่สแกนแบบเละๆ ความไม่เป็นระเบียบเรียบร้อย สแกนมาเอียงบ้าง ตัวอักษรซีด เข้มเกิน ทำให้ยากต่อการที่จะอ่านเอกสาร อีกอย่างเมื่อเราดูประกาศ/คำสั่ง/ระเบียบ ของรัฐที่ถูก Publish ขึ้น Website ของหน่วยงานต่างๆ พบว่ามีแค่สกุลไฟล์ .pdf ไม่พบสกุลไฟล์อื่นๆ เช่น text เป็นต้น และเนื่องจากนโยบายการผลักดันการทำ E-Government และการเปิดเผยข้อมูลของรัฐ (OPEN DATA) เมื่อสำรวจดูหลายๆเว็บกลับพบว่ายังเป็นสกุลไฟล์ .pdf ไม่มีสกุลไฟล์อื่นๆ ที่เป็นสกุลไฟล์ที่หลากหลาย เพื่อนำไปต่อยอดและวิเคราะห์ข้อมูล ดังนั้นการนำเทคโนโลยี OCR มา Apply กับ เอกสารราชการไทย จึงเป็นเรื่องที่สำคัญอย่างมาก
3. ทำไมต้อง TH Sarabun ?
เนื่องจากระเบียบการจัดทำ และออกหนังสือประกาศและคำสั่งของทางราชการไทย เพื่อให้เป็นมาตรฐานเดียวกันทั่วประเทศนั้นได้มีการกำหนดการใช้งาน ฟอนต์มาตรฐานแห่งชาติ (National Font) สำหรับการออกหนังสือราชการทุกประเภท คือ ฟอนต์ตระกูล TH Sarabun ขนาด 16–20 px
และเมื่อดูในส่วนของ Repository ของ Langdata_lstm Tesseract ในส่วนของรายชื่อฟอนต์ที่ใช้ในการ Train tesseract นั้นไม่พบฟอนต์มาตรฐานราชการไทย (ตระกูลฟอนต์ที่ขึ้นต้นด้วย TH) แม้แต่ฟอนต์เดียว หรือแม้กระทั่งฟอนต์ที่มีลักษณะคล้ายกับ ฟอนต์มาตรฐานราชการไทยที่อยู่ใน Google fonts เช่น Sarabun

4. ขั้นตอนการเลือก Tools ในการทำ OCR
ในการเลือก Tools ที่จะมาใช้ทำงาน OCR ได้ความอนุเคราะห์จากพี่ชารินทร์ให้ลองทดสอบตัว Tools OCR อยู่ทั้งหมด 2 ตัว คือ
- Tesseract OCR
- Easy OCR
โดยเราจะใช้ Test set คือประโยค ข้อความ จากเอกสารราชการจริง มีการปรับแต่งสี ปรับแต่งความชัด เพื่อจำลองความหลากหลายในการแสดงผลที่ไม่อาจคาดเดาได้ของเอกสารฯ
4.1 ขั้นตอนการ การวัดผล Tools OCR
- CER (Character Error Rate) Compare correct string and result from OCR string
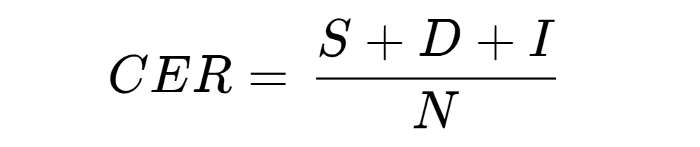
- n คืออักษรของ reference (ประโยคจริง)
- i คืออักษรที่ต้องใส่เพิ่มใน prediction เพื่อให้มันเหมือนประโยคจริง
- d คืออักษรที่ต้องลบออกจาก prediction เพื่อให้มันเหมือนประโยคจริง
- s คืออักษรที่ต้องแทนที่ใน prediction เพื่อให้มันเหมือนประโยคจริง
- เลือก combination i+d+s ที่ต่ำที่สุด (แก้น้อยสุด) แล้วหารด้วย n เพื่อให้ได้ CER
2. Length Correct String and length OCR String
คือการนับจำนวน String จากประโยคที่ถูกต้อง (Correct Sentences) และประโยคจาก OCR
4.2 ผลสรุปการเลือก Tools
เลือกใช้ Tesseract เพราะ
- มีความแม่นยำที่มากกว่า Easy OCR แต่ไม่มากเท่าใด
- มี Tools ที่ครบต่อการ Fine-tune และ Train
5.มาเตรียม Tools สำหรับการ Train & Fine tune Tesseract
- Code editor
- Python 3
- OS แนะนำเป็น Linux เช่น Ubuntu 20.04 แต่ถ้าใช้ Windows ให้ลง WSL เป็น Ubuntu version 20.04 ขึ้นไปครับ
- Tesseract 4.1
6. มาเตรียม Train Validation Set กับ Test Set
ก่อนที่จะไปดูรายละเอียดนั้นผมขอเตือนไว้ก่อนว่า
#อย่าเชื่อใจ Dataset ที่ยังไม่ได้คลีนด้วยตัวเอง ผมเจ็บมาเยอะะะ ;-;
เมื่อลองสำรวจและพิจารณา Train Validation Set (tha.training_text) ที่เป็น default พบว่าประโยคที่ไว้สำหรับ Train นั้นมีความที่ดูมั่วๆพอสมควร ดังนั้นจึงได้มีการทำ Train Validation Set ใหม่ทั้งหมด โดยที่ในการเตรียม Dataset เพื่อมาทำ train set นั้นได้ทำการใช้ Data จาก
- พาดหัวข่าวจากเว็บประชาไทย
- พาดหัวข่าวจากเว็บไทยรัฐ
- ถ้อยคำแถลงการนายกรัฐมนตรี
- รัฐธรรมนูญแห่งราชอาณาจักรไทย
โดยดึงข้อมูลจาก file .csv .txt จำนวน ทั้งสิ้นประมาณ 60000 ประโยค
- Train set 50000 ประโยค
- Validation Set จำนวน 10000 ประโยค
โดยที่ประโยคทั้งหมดนั้นจะนำไปแทนที่ประโยคใน tha.training_text เดิมที่มีอยู่
ในส่วนของ Test set สำหรับการวัดประสิทธิภาพ นั้นมีจำนวน 110 รูปสกุลไฟล์ .jpg โดยแบ่งเป็น
- รูปที่ 1–20 ขนาด zoom 180%

- รูปที่ 21–30 ขนาด zoom 125%
- รูปที่ 31–40 ขนาด zoom 100%

- รูปที่ 41–50 ขนาด zoom 90%
- รูปที่ 51–100 ขนาด zoom 80% (Preview เห็นทั้ง A4)
- รูปที่ 88–100 ขนาด zoom 80% (ตัวอักษรไม่ชัดหรือสีซีด)

- รูปที่ 101–110 ขนาด zoom 150% (มีการขีดทีบตัวอักษร รอยประทับตราทางราชการ ตัวอักษรเอียง)
7. ขั้นตอนการ Fine tune และ Train Tesseract
ในส่วนขั้นตอนนี้บอกเลยว่าปัญหาเยอะมากกก ท้อจนแบบท้อแล้วท้ออีก เจอปัญหาทั้ง Core Dumped , Memory leak หลายรอบจนต้องเปลี่ยนเครื่อง resource ใหม่แล้วเกือบทำ resource เขาล่มก็มีมาแล้วว ซึ่งทั้งหมดนี้ผมขอขอบคุณ พี่ที่เปรียบเหมือนกับแสงสว่างที่ปลายอุโมงค์ ก็คือพี่ต้นตาล แห่ง PyThaiNLP นั้นเองงงงงงงง #กราบพี่ต้นตาล #ไหว้ย่อครับบบ
ในการ Fine tune และ Train Tesseract นั้นตามหลักการที่ผมได้ทำการศึกษามาจะแบ่งออกเป็น 2 รูปแบบได้แก่
- การ Fine tune จาก tha.trainneddata และ Train เพิ่มด้วย Script .sh
ซึ่งในวิธีจะเหมาะกับเอกสารที่เรารู้ฟอนต์หรือฟอนต์ที่แน่นอนของเอกสารนั้นเอง
2. การ Fine tune จาก tha.trainneddata และ Train เพิ่มด้วย Tesstrain
ซึ่งในวิธีการนี้จะเหมาะกับรูปภาพเก่าๆที่มีตัวอักษร โดยมี dataset อันได้แก่
- File รูปภาพประโยค
.tif,.png,.bin.png,.nrm.png - File .gt.txt ใน Format ของ (Unix LF)
โดยที่ ชื่อไฟล์ทั้งสองต้องเหมือนกัน ซึ่งถ้าถามว่าทำไมต้องมีไฟล์ .gt.txt เพราะเพื่อให้เป็นการให้ Model Tesseract เรารู้ว่าประโยคในรูปภาพ อ่านเป็นตัวอักษรแล้วคืออะไร ซึ่งถ้าเปรียบเทียบในกระบวนการสร้าง AI ด้วย Fast.AI นั้นก็คือการใส่ Lable ให้กับตัว Image นั้นเอง
ซึ่งในกระบวนการนี้ผมได้ทำการทดลองทั้ง 2 วิธี และได้เลือกวิธีที่จะใช้ในครั้งนี้ คือการ Fine tune จาก tha.trainneddata และ Train เพิ่มด้วย Script .sh ซึ่ง Process นี้ได้รับความช่วยเหลือจากพี่ต้นตาลแห่ง PyThaiNLP ช่วยในการ Run Script มีลำดับดังนี้ โดยใช้ notebook script_basic.ipynb หรือ script_config_error.ipynb ในการรัน Script .Sh โดยแต่ละไฟล์มีหน้าที่ดังนี้
- คือการ Gen dataset จาก tha.training_text ที่เราได้ทำการใส่ Data ใหม่ที่เราเตรียมไว้จำนวน 60000 ประโยค generate_train_ds.sh

ระวังเรื่องของ Memory leak ใน Process นี้แนะนำ Tools ในการ Train และ Fine-Tune ซึ่งปัญหาเกิดจากตัว Tool ของ Tesseract ตาม Repo นี้ : https://github.com/tesseract-ocr/tesseract/commit/345e5ee
2. คือการรัน requirements ที่ถูก generate จาก ขั้นตอน (1) และการเลือก Model tha.traineddata เพื่อมาทำการ Fine tune และ Train ด้วย Custom Dataset ของเรา (extract_lstmf.sh)

3. จากนั้นจะเป็นการ extract ไฟล์.tif ที่ถูก Generate จากขั้นตอนที่ 1 โดยเมื่อเริ่มต้นกระบวนการจะมีการนำไฟล์จาก .tif ขั้นตอน 1 มาแยกเป็นประโยคเพื่อที่จะทำการ Train ต่อไป(eval.sh)

4.ขั้นตอนการ Finetune Tesseract ด้วย Custom Dataset ที่เราเตรียมไว้ (finetune.sh) โดยเมื่อเสร็จสิ้นกระบวนการนี้ จะได้ ค่า CER : Character Error Rate และค่า Error rate เฉลี่ย
5. ขั้นตอนการ Export Model เพื่อนำออกไปใช้งาน (combine.sh & eval2.sh)
โดยเราจะได้ Model ในสกุลไฟล์ .trainneddata
8. วัดประสิทธิภาพ Model Tesseract ที่ถูกเทรนด้วยฟอนต์ TH Sarabun (THND MODEL)
ในการวัดประสิทธิภาพนั้นเราจะใช้หลักการเดียวกับ 4.1 โดยที่เราจะวัดประสิทธิภาพเทียบกับ API T-OCR ของทาง AI For Thai และ Tesseract (tha.trainneddata) ที่ไม่ได้ผ่านการ Fine tune และการ Train
8.1 ผลสรุป
เมื่อได้ทำการ Fine tune และ Train Model Tesseract ด้วย Custom Dataset แล้ว export model (THND) ได้ค่า
Character Error Rate ดังนี้
- T-OCR AI for Thai = 13.59648545 %
- Tesseract (Without Fine-tune) = 5.42347 %
- Tesseract (THND Model) = 4.8067725 %
ถึงแม้ว่าค่า Character Error Rate จะลดลงไม่มาก แต่เมื่อสำรวจจาก การอ่านข้อความประโยคจาก Test set พบว่า เมื่อยังไม่ได้ Fine-Tune Tesseract สามารถอ่านตัวเลขไทยได้น้อย ขาดความแม่นยำ ตัวอักษรบางตัวยังมีผิดพลาด แต่เมื่อทำการ Fine-Tune และ Train เป็นที่เรียบร้อยแล้วพบว่า THND Model มีประสิทธิภาพในการอ่านตัวเลขไทย ตัวอักษรไทย ได้เพิ่มมากขึ้นจากเดิม
9. ทำ Web Application ไว้ทดสอบ THND Model Tesseract
ในการทำ Web Application เพื่อทดสอบ Model ของเรานั้น เราเลือกใช้ Node.JS ในการ Develop เว็บในครั้งนี้
ในส่วนของการจำลองการทำงานของ Tesseract บน Local เพื่อใช้ในเว็บนั้น เลือกใช้ Javascript Framework ชื่อว่า Tesseract.JS
Link: https://tesseract.projectnaptha.com/
โดย Model ใช้เป็น THND Model (Model ที่เราได้ทำการ Train และ Fine-tune) ด้วย Custom Dataset นั่นเอง
Link: https://github.com/jeromewu/tesseract.js-custom-traineddata
ในการ Deploy นั้นใช้วิธีการ forward port จาก Server ผ่านตัว DDNS เพื่อให้ ภายนอกสามารถ Access เข้ามาทดลองใช้งานได้
10. สรุปปิดท้าย

ปัจจุบันเราไม่สามารถที่จะปฏิเสธได้ว่า OCR นั้นช่วยอำนวยความสะดวกให้กับพวกเราอย่างมากมาย ช่วยลดเวลาการทำงาน ต่างๆ ในการ Finetune Tesseract ด้วย Custom Dataset นั้นสามารถช่วยลดค่า CER : Character Error Rate ได้จริงแต่ด้วยความที่อักษรไทย ยังมีองค์ประกอบหลายส่วน เช่น สระ วรรณยุกต์ สระลอย ตัวเลขไทย เลยอาจทำให้ result ออกมาผิดได้ ดังนั้นโครงการนี้ในอนาคตจะมีการพัฒนาต่อเรื่อยๆ เพื่อให้มีความแม่นยำมากที่สุดพร้อมต่อการแจกจ่ายและใช้เป็น Open Source ของวงการ OCR ไทยต่อไป :)
หลายๆคนมักจะบอกว่าการทำ OCR เป็นง่ายที่ง่าย ผมเห็นด้วยครับมันง่ายครับ แต่ทำไมกลับไม่มีใครที่คิดลงมือจะทำ? ทั้งๆที่ Tools ของมันครบคันมากๆ หลายๆที่ หลายๆบริษัทก็พยายามชูฟีเจอร์นี้ มันก็เหมือนกับการมีสูตรอาหารที่คุณชอบอยู่ในมือไม่ได้ด้อยกว่าใคร มีวัตถุดิบ ของทุกอย่างครบคัน ขาดแค่คนลงมือทำ แต่ก็ยังไปซื้ออาหารนั้นมาทานอยู่ประจำ ดังนั้นผมขอที่จะเป็นคนพัฒนา OCR เป็นพ่อครัวที่จะทำเมนู OCR Thai เพื่อให้ทุกคนมี Tools OCR Thai ที่ดีไปใช้งาน และเป็นการพัฒนาวงการนี้ให้ใหญ่ขึ้นอีกด้วยครับ
#เตรียมพบกับ THND OCR The Series Season 2 เร็วๆนี้ 📰🔜
สำหรับวันนี้ไม่ขอช้าง 🐘 ไม่ขอม้า 🏇🏼แต่ขอลาไปก่อน👋🏼 ขอบคุณครับบ 🙏🏼
Resource link for debugging and learn
https://stackoverflow.com/questions/51080147/training-tesseract-4-with-images-instead-of-font
https://github.com/tesseract-ocr/tesstrain
https://github.com/tesseract-ocr/tesseract
https://github.com/tesseract-ocr/tesstrain/issues?q=is%3Aissue+is%3Aopen
https://githubmemory.com/repo/livezingy/tesstrainsh-win
https://www.thaiall.com/blog/tag/government-font/
Special Thank 🙏
- AI Builders
- The mentor of AI Builders
- PyThaiNLP
- Teacher Viratchai Junthawong YRC Science and Technology Department

{kind=link}